











Docker Swarm 之 节点(Node)
摘要
-
本文介绍 Docker Swarm 的 节点管理
Docker Swarm 简介
-
Docker Swarm 是 Docker 官方提供的一个集群管理工具,基于 Docker Swarm 可以快速实现 Docker 集群的管理。
-
从 Docker v1.12 版本开始,Docker Swarm 已经包含在 Docker Engine 中,不需要单独安装。
-
Docker Swarm 具有服务编排、服务负载均衡、服务升级和服务失败迁移等功能。
-
Docker Swarm 集群中的节点分为两种类型:管理节点(Manager Node)和工作节点(Worker Node),管理节点负责集群的管理,工作节点负责运行容器。
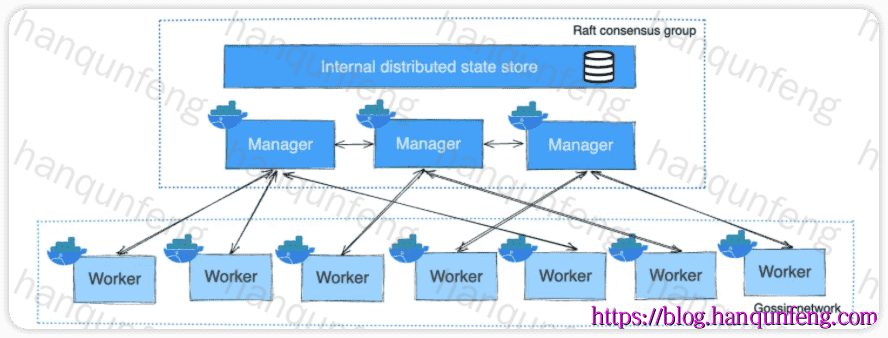
-
以下是 Docker Swarm 中 管理节点(Manager Node) 和 工作节点(Worker Node) 的对比
| 特性/功能 | 管理节点(Manager Node) | 工作节点(Worker Node) |
|---|---|---|
| 角色 | 负责集群管理和决策 | 执行分配的服务任务 |
| 是否参与服务运行 | 可以运行服务任务,也可以只做管理(可配置) | 仅运行服务任务,不参与管理决策 |
| 集群状态维护 | 维护整个 Swarm 的状态(使用 Raft 协议) | 不维护集群状态 |
| 调度任务 | 决定将服务任务分配给哪个节点 | 不负责调度,只执行接收到的任务 |
| 管理命令处理 | 接收并处理 Swarm 管理命令(如创建服务、扩缩容等) | 不处理管理命令 |
| 数据一致性 | 需要保持一致性(至少 3 个管理节点形成高可用) | 不涉及一致性 |
| 资源要求 | 相对较高,需要承担管理和协调开销 | 相对较低,专注于运行容器 |
| 可用性要求 | 通常配置奇数个(3、5、7…)以保障高可用 | 可根据需要自由扩展或缩减 |
| 节点加入方式 | 通过 manager token 加入 Swarm | 通过 worker token 加入 Swarm |
| 故障影响 | 多个管理节点故障可能影响整个 Swarm 的控制能力 | 部分工作节点故障通常不会影响 Swarm 的管理能力 |
-
manager 节点通常配置为奇数个,默认创建集群的节点就是 manager 节点,并且是 manager 节点中的的 Leader 节点。Leader 节点负责管理集群,Leader 节点在集群中只能有一个。当 Leader 节点故障时,Swarm 会自动从其它 manager 节点中选举出一个新的 Leader 节点。
-
worker 节点是运行容器的节点,不参与机器的管理和调度,不支持执行任何和集群管理相关的操作。
-
默认情况下,manager 节点也会参与接收运行容器的任务,但是可以通过设置来指定 manager 节点不参与接收任务。
-
manager 节点和 worker 节点可以通过“升级”和“降级”相互转换。
搭建Swarm集群
-
本教程需要五台安装了Docker且能够通过网络通信的 Linux 主机,这些主机可以是物理机、虚拟机、Amazon EC2 实例,也可以以其他方式托管。
-
其中三台机器是管理节点(称为manager1,manager2,manager3),另外两台是工作节点(worker1和worker2)。
| IP 地址 | HostName | 角色类型 |
|---|---|---|
| 10.211.55.10 | manager1 | 管理节点 |
| 10.211.55.11 | manager2 | 管理节点 |
| 10.211.55.12 | manager3 | 管理节点 |
| 10.211.55.13 | worker1 | 工作节点 |
| 10.211.55.14 | worker2 | 工作节点 |
-
所有主机上必须开启如下端口,以确保Docker Swarm 集群正常通信:
| 端口号 | 协议 | 用途说明 |
|---|---|---|
| 2377 | TCP | 管理器节点之间通信(管理指令和加入集群) |
| 7946 | TCP/UDP | 节点发现和通信(集群内部发现机制) |
| 4789 | UDP | 覆盖网络流量(VXLAN,用于容器间网络) |
1 | # 开放 Swarm 管理节点通信端口 |
-
所有主机必须时间一致
1 | # 同步系统时间 |
创建集群
-
在 manager1 节点上执行如下命令来创建一个新的swarm集群
1 | # 查看当前docker的swarm模式是否开启 |
安装 yq 工具
- yq 是 yaml 的命令行处理工具,具体参考yq
1 | # 下载 yq 最新版本 |
添加 manager 节点
-
获取 manager 节点的 token
1 | # 在 manager1 上运行 |
-
将 manager2 和 manager3 加入 swarm 集群
1 | # 分别在 manager2 和 manager3 上运行如下命令, |
添加 worker 节点
-
获取 worker 节点的 token
1 | # 在 manager1 上运行 |
-
将 worker1 和 worker2 加入 swarm 集群
1 | # 分别在 worker1 和 worker2 上运行如下命令, |
查看集群状态
-
在 manager1 上执行如下命令
1 | docker info --format '{{json .Swarm}}' | jq '{LocalNodeState,NodeID,NodeAddr,RemoteManagers,Nodes,Nodes,Managers,ControlAvailable}' | yq -P |
查看集群内节点信息
-
在 任意 manager 节点上运行如下命令
1 | # 在 manager1 上运行,列出所有节点信息,只有 manager 节点支持 node 相关命令 |
| 字段名 | 示例值 | 中文含义 |
|---|---|---|
| ID | kp2zerd28xgz5mmglnje0jp22 |
节点的唯一 ID(在 swarm 集群中自动生成的唯一标识符) |
| HOSTNAME | manager1 |
节点的主机名(即加入 swarm 集群时该节点的 hostname) |
| STATUS | Ready |
节点的状态: • Ready:节点正常运行中• Down:节点离线或无法通信• Paused:暂停• Drain:排空,正在迁移任务 |
| AVAILABILITY | Active |
节点的可用性设置: • Active:节点可以调度任务(默认)• Pause:暂停调度新任务• Drain:迁移任务并不再调度 |
| MANAGER STATUS | Leader / Reachable / 空 |
仅适用于管理节点: • Leader:当前 swarm 的主节点(负责协调)• Reachable:集群中可通信的管理节点• 空:表示这是一个工作节点(非管理节点) |
| ENGINE VERSION | 26.1.3 |
Docker 引擎的版本号(即该节点上运行的 Docker 版本) |
docker swarm集群管理
| 命令 | 中文含义 |
|---|---|
ca |
显示和轮换 Swarm 的根证书(CA) |
init |
初始化一个新的 Swarm 集群 |
join |
将当前节点加入到 Swarm 中,作为工作节点或管理节点 |
join-token |
管理用于加入 Swarm 的令牌(查看或重新生成) |
leave |
当前节点离开 Swarm 集群 |
unlock |
解锁被加密的 Swarm(用于恢复 Manager 节点) |
unlock-key |
管理 Swarm 的解锁密钥(查看、备份等) |
update |
更新 Swarm 集群的全局配置(如加密、日志等) |
-
docker swarm init: 初始化 Swarm 集群(只在首次创建时使用)
1 | docker swarm init --advertise-addr 10.211.55.10 |
-
docker swarm join-token: 生成加入集群的令牌
1 | # 生成 worker 节点的令牌 |
-
docker swarm join: 加入 Swarm 集群(在已有 Swarm 集群中加入节点时使用)
1 | docker swarm join --token <token> 10.211.55.10:2377 |
-
docker swarm leave: 使当前节点离开 Swarm 集群(从 Swarm 集群中移除节点时使用)
1 | # worker 节点离开集群 |
-
docker swarm update: 更新 Swarm 集群配置
1 | # 开启Swarm集群锁定,只针对manager节点,manager节点重启后需要解锁才能恢复,下面的密钥不需要记住,通过`docker swarm unlock-key`命令查看 |
-
docker swarm unlock-key: 获取Swarm集群的解锁密钥,该命令可以判断Swarm集群是否被锁定
1 | # 获取Swarm集群的解锁密钥 |
-
docker swarm unlock: 手动解锁当前 manager 节点,使其在启用 autolock 时恢复功能
1 | # 如果Swarm集群设置为锁定,则重启manager2上的docker服务后将无法运行node管理命令 |
docker node节点管理
-
节点管理相关命令,只能在 管理节点 上执行
| 命令 | 中文含义 |
|---|---|
demote |
将一个或多个管理节点降级为工作节点 |
inspect |
显示一个或多个节点的详细信息 |
ls |
列出 swarm 集群中的所有节点 |
promote |
将一个或多个工作节点提升为管理节点 |
ps |
查看一个或多个节点上正在运行的任务(默认当前节点) |
rm |
从 swarm 集群中移除一个或多个节点 |
update |
更新节点的元数据(如标签、可用性等) |
-
docker node ls: 列出 swarm 集群中的所有节点
1 | docker node ls |
-
docker node inspect <node_id>/<hostname>: 查看指定节点的详细信息
1 | docker node inspect --pretty manager1 |
-
docker node update <options> <node_id>/<hostname>: 更新节点的元数据
1 | # 设置节点为不可用 |
-
docker node demote <node_id>/<hostname>: 将管理节点降级为工作节点
1 | docker node demote manager1 |
-
docker note promote <node_id>/<hostname>: 将工作节点升级为管理节点
1 | docker node promote worker1 |
-
docker node rm <node_id>/<hostname>: 从 swarm 集群中移除一个节点
1 | docker node rm manager1 |
节点管理常见情况
如何正确的删除一个节点
-
1.如果是 manager 节点,先将 manager 节点降级为 worker 节点
1 | docker node demote manager1 |
-
2.退出集群
1 | # 在要退出集群的节点上执行 |
-
3.删除节点
1 | docker node rm manager1 |
节点被退群或删除后,其上运行的service会怎样?
-
用一个示例来说明,先在 manager1 节点上创建一个 service
1 | # --replicas 10 表示启动 10 个 nginx 容器,swarm集群有5个节点,所以启动10个nginx容器,每个节点会启动2个nginx容器 |
-
查看service状态
1 | docker service ps my-nginx |
-
这时将 worker2 从集群中退群
1 | # 在worker2节点执行 |
-
再次查看service状态
1 | docker service ps my-nginx |
-
如果不退群直接删除节点呢?这次我们直接删除 worker1 节点
1 | # 删除 worker1 节点 |
节点被退群或删除后是否可以重新加入集群
-
节点被退群或删除后,可以通过
docker swarm join命令重新加入集群 -
若节点是被强制删除,而没有退群,则重新加入集群时需要先通过
docker swarm leave命令退群后再加入集群
如果Swarm集群设置为锁定,则重启manager节点后无法提供集群服务的解决方法
1 | # 这里重启一个manager节点的docker服务 |
Swarm 集群锁定功能的作用及使用场景
-
作用
| ✅ 作用 | 📋 说明 |
|---|---|
| 加密保护管理密钥 | 管理器节点之间的数据(如 Raft 日志)虽然默认加密,但密钥保存在内存中。启用锁定功能后,密钥在节点重启时不会自动加载,必须手动提供解锁密钥才能恢复。 |
| 防止节点被非法重启后加入集群 | 如果攻击者获得了管理节点的物理访问权限(如重启、磁盘克隆等),锁定功能可以防止其自动控制或重新加入 Swarm 集群。 |
-
场景
| 场景类型 | 具体描述 |
|---|---|
| ✅ 适合场景 | 对安全性要求高的生产环境 |
| 部署在不可信或共享物理环境中 | |
| 云服务器、数据中心有专人运维管理解锁过程 | |
| 希望防止物理/远程入侵者恢复管理器角色的公司 | |
| ❌ 不适合场景 | 需要自动化部署或重启的 CI/CD 系统 |
| 测试环境或开发集群 | |
| 无人值守、要求高可用自动恢复的部署系统 |
-
总结
| 项目 | 是否推荐 |
|---|---|
| 安全性 | ✅ 强烈推荐启用(尤其在生产环境) |
| 自动化 | ❌ 不推荐(增加人工干预步骤) |
| 解锁方式 | 解锁命令 + unlock key |
| unlock key 丢失后果 | 可能需要重建 Swarm(除非提前备份) |
docker swarm ca 是做什么用的?
-
docker swarm ca命令是用来 管理 Swarm 集群中的根证书颁发机构(CA) 的工具。具体功能包括:
| 子命令/参数 | 说明 |
|---|---|
docker swarm ca |
查看当前 Swarm 的根 CA 公钥(PEM 格式) |
docker swarm ca --rotate |
轮换根 CA,用于安全更新 |
-
Swarm 中的证书是干什么用的?
| 用途 | 说明 |
|---|---|
| ✅ 节点身份验证 | 每个节点加入集群时,都会收到一个由根 CA 签发的 TLS 证书,用于证明它的身份。 |
| 🔐 通信加密 | 节点之间(Manager ↔ Worker)的通信通过 TLS 进行加密。 |
| 🔄 自动轮换 | Docker 会自动为每个节点签发短期证书(默认有效期 90 天)并定期自动轮换。 |
-
Swarm 在后台自动管理证书,所以你不需要手动处理它们。不过,你可以在每个节点上找到它们的位置:
1 | cd /var/lib/docker/swarm/certificates |
只让 Manager 做管理,不运行服务
-
节点的
AVAILABILITY有三种:active、pause、drain。
| 状态 | 说明 |
|---|---|
active |
可调度,Swarm 可以在此节点上运行服务任务(默认) |
pause |
暂停调度,不会分配新任务,但保留已有任务 |
drain |
排空模式,不可调度,Swarm 会将该节点上的任务迁移到其他节点,新的任务将不会分配到此节点 |
-
如果你希望 Swarm Manager 节点仅参与管理工作,而不运行服务任务(task),你可以通过 设置节点的可调度状态为“不可调度” 来实现这一目标。
1 | # 设置 manager1 节点为“不可调度”,即 排空模式 |